Algoritma K-Nearest Neighbor (KNN) adalah sebuah metode klasifikasi terhadap sekumpulan data berdasarkan pembelajaran data yang sudah terklasifikasikan sebelumya. Termasuk dalam supervised learning, dimana hasil query instance yang baru diklasifikasikan berdasarkan mayoritas kedekatan jarak dari kategori yang ada dalam K-NN.
Tujuan dari algoritma ini adalah untuk mengklasifikasikan obyek baru berdasarkan atribut dan sample-sample dari training data.
Kelebihan dan Kekurangan KNN (K-Nearest Neighbor) ..
==> Kelebihan KNN (K-Nearest Neighbor)
- Sangat nonlinear.
- Mudah dipahami dan diimplementasikan.
==> Kekurangan KNN (K-Nearest Neighbor)
- Perlu menunjukkan parameter K (jumlah tetangga terdekat).
- Tidak menangani nilai hilang (missing value) secara implisit.
- Sensitif terhadap data pencilan (outlier).
- Rentan terhadap variabel yang non-informatif.
- Rentan terhadap dimensionalitas yang tinggi.
- Biaya komputasi cukup tinggi karena diperlukan perhitungan jarak dari setiap sampel uji pada keseluruhan sampel latih.
Study Kasus
Data yang digunakan yaitu Data Cryotherapy Dataset diperoleh dari UCI Machine Learning Repositor
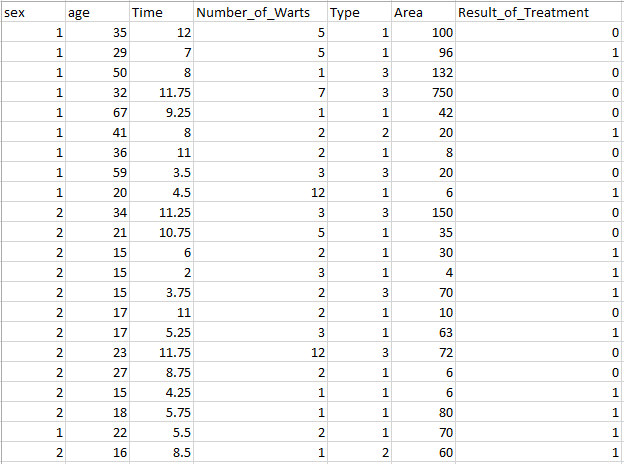
Berdasarkan Data Cryotherapy Dataset dapat diketahui bahwa terdapat 90 data yang menjelaskan tentang hasil perawatan kutil. Dalam data ini terdapat 7 variabel yaitu Sex , Age , Time , Number of Warts , Type , Area dan Result of Treatment. Klasifikasi Data Cryotherapy yaitu Sex : 1 = laki-laki 2 = wanita ; Type : 1 = kutil biasa 2 = kutil plantar 3 = kutil lainnya ; Result of Treatment : 1 = sembuh 2 = tidak sembuh.
Selanjutnya, klasifikasi menggunakan K-Nearest Neighbor dapat dilakukan dalam phyton seperti berikut.
Pertama, import package pandas dan numpy.
import pandas as pd
import numpy as np
Kedua, menginput data Cryotherapy dengan format .csv .
cryotherapy = pd.read_csv(“cryotherapy.csv”)
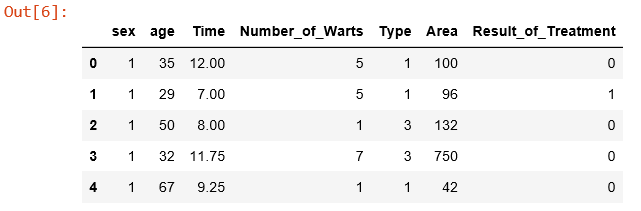
Ketiga, membaca data Cryotherapy dengan 5 data teratas.
cryotherapy.head()
Keempat, menampilkan informasi tentang jenis data Cryotherapy.
cryotherapy.info()
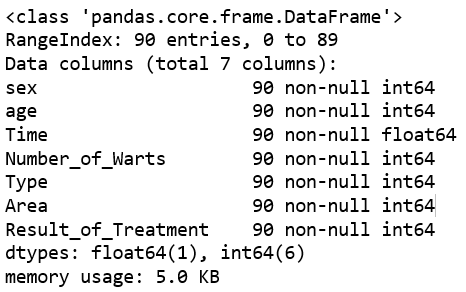
Berdasarkan output diatas, maka dapat diketahui bahwa dari data Cryotherapy tipe datanya ada float dan integer. Terdapat tipe data float sebanyak 1 dan tipe data integer sebanyak 6.
Kelima, menentukan variabel independen dari data sehingga, menghapus variabel dependen yaitu Result of Treatment.
# Variabel independen
x = cryotherapy.drop([“Result_of_Treatment”], axis = 1)
x.head()
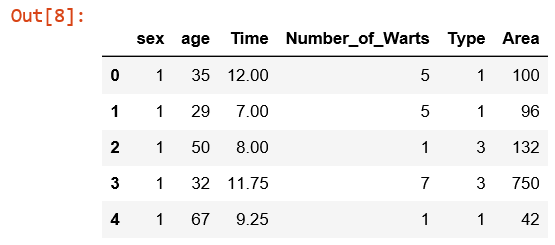
Berdasarkan hasil output diatas yang termasuk variabel dependen yaitu Sex , Age , Time , Number of Warts , Type dan Area. Dalam variabel dependen yang terdapat klasifikasi yaitu Sex dan Type.
Keenam, menampilkan data variabel dependen yaitu Result of Treatment.
# Variabel dependen
y = cryotherapy[“Result_of_Treatment”]
y.head()
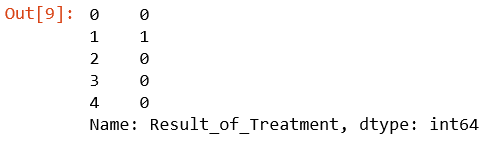
Ketujuh, untuk melakukan klasifikasi K-Nearest Neighbor aktifkan package sklearn.
from sklearn.model_selection import train_test_split
Kedelapan, membagi data training dan data testing.
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 123)
Kesembilan, mengubah skala data dengan mengaktifkan package dan menuliskan syntax.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
Kesepuluh, mengaktifkan package untuk klasifikasi KNN dengan import KNeighborsClassifier dari package sklearn.
from sklearn.neighbors import KNeighborsClassifier
Kesebelas, Mengaktifkan fungsi klasifikasi.
# Mengaktifkan fungsi klasifikasi
klasifikasi = KNeighborsClassifier(n_neighbors=5)
Keduabelas, Menginput data training pada fungsi klasifikasi.
# Memasukkan data training pada fungsi klasifikasi
klasifikasi.fit(x_train, y_train)

Ketigabelas, Menentukan hasil prediksi dari x_test.
# Menentukan hasil prediksi dari x_test
y_pred = klasifikasi.predict(x_test)
y_pred
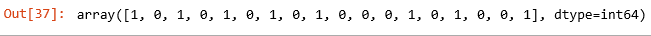
Keempatbelas, menentukan probabilitas dari hasil prediksi.
# Menentukan probabilitas hasil prediksi
klasifikasi.predict_proba(x_test)

Kelimabelas, untuk menghitung confussion matrix maka import package confussion matrix.
from sklearn.metrics import classification_report, confusion_matrix
Keenambelas, menampilkan confussion matrix hasil prediksi klasifikasi.
print(confusion_matrix(y_test, y_pred))

Ketujuhbelas, menampilkan hasil ketepatan prediksi dengan menggunakan nilai precision, recall dll seperti berikut.
print(classification_report(y_test, y_pred))
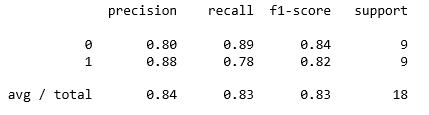
Berdasarkan nilai ketepatan prediksi diatas maka dapat diketahui bahwa 0.84 merupakan nilai rata-rata yang cukup besar dari perhitungan yang lainnya maka hal itu menandakan ketepatan prediksi yang paling baik yaitu pada bagian precision dengan nilai 0.84 .
Kedelapanbelas, untuk mengitung nilai akurasi maka import accuracy score.
niali akurasi
from sklearn.metrics import accuracy_score
accuracy= accuracy_score(y_test, y_pred)
accuracy

Berdasarkan nilai output diatas , maka dapat diketahui bahwa nilai akurasi yang didapatkan yaitu 0.8333 .
Tidak ada komentar:
Posting Komentar